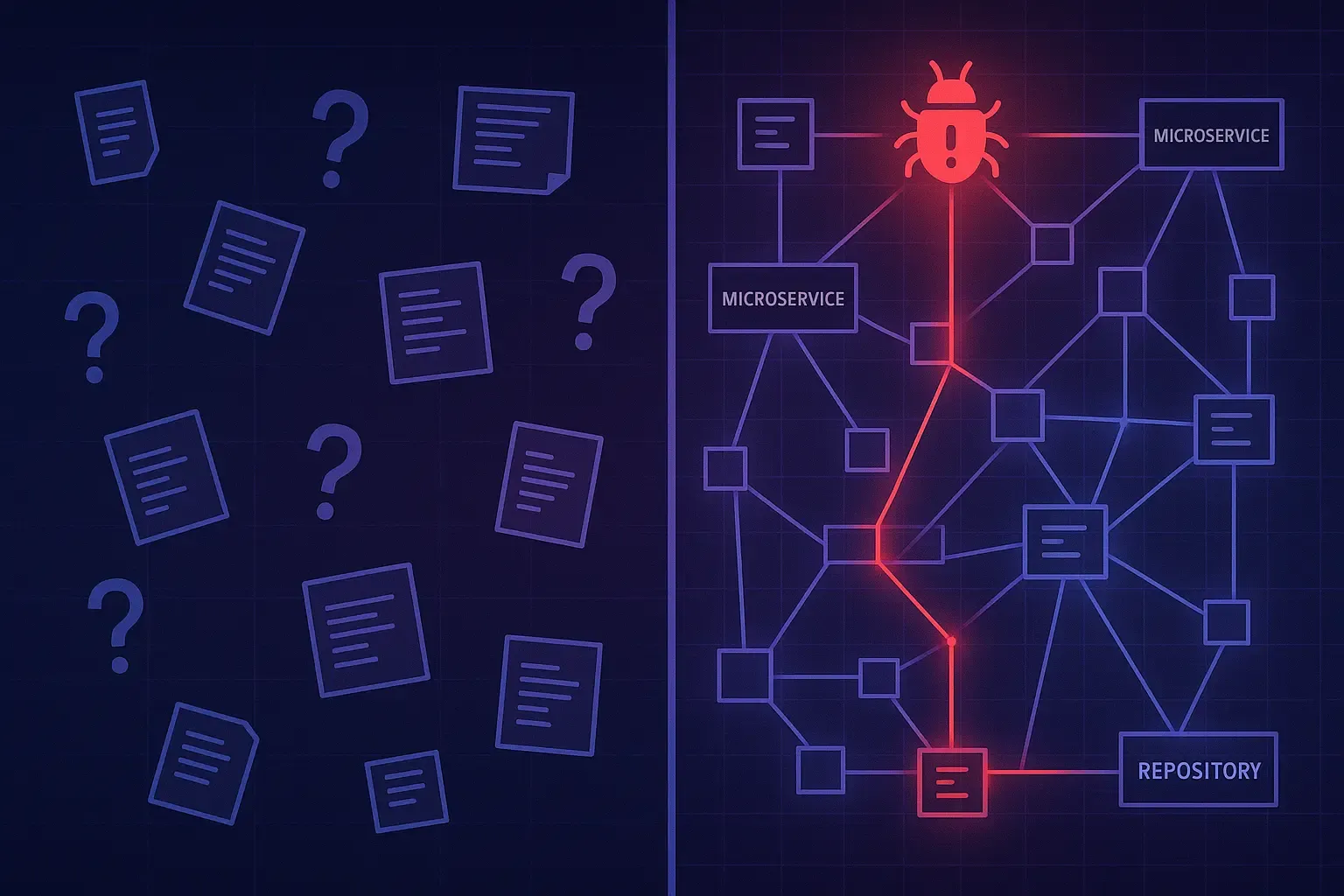
How Big Teams Trace a Bug Across Ten Services
It’s 2 PM on a Tuesday. Production alerts are firing. Users can’t complete checkout.
You pull up the logs. The error originates in the payment service. But the payment service doesn’t actually process payments—it calls the billing service, which calls the pricing service, which validates against the product catalog service. Somewhere in that chain, something broke.
You have thirty minutes before the VP of Engineering starts asking questions. You have ten repositories to search through. Good luck.
The Microservices Reality
Microservices architecture solved real problems. Independent deployments. Team autonomy. Scaling specific services without touching others. At enterprise scale, these benefits are substantial.
But microservices also created a new category of pain: the cross-service bug.
When your system was a monolith, tracing a bug meant following a stack trace. When your system is ten services, tracing a bug means following network calls across repository boundaries, each owned by a different team, each with its own conventions and deployment schedules.
The average change at scale touches four services, according to engineering discussions on HackerNews. And touching one triggers releases in two or three others. Finding the root cause isn’t a search problem—it’s a treasure hunt across organizational boundaries.
What Plain Search Gives You
You search for the error message. You find it in the payment service logs.
You search for the function that threw the error. You find the implementation, but it just calls an external service.
You search for that service’s endpoint. You find three different implementations because someone refactored six months ago and forgot to delete the old version.
You search for who calls what. You find import statements scattered across repositories, but you can’t tell which are active and which are dead code from abandoned features.
Forty-five minutes have passed. You still don’t know where the bug is. You’ve context-switched across nine browser tabs, four repositories, and two Slack threads asking teammates for tribal knowledge.
This is the 23-minute recovery cost, multiplied. Research shows that every interruption costs developers about 23 minutes to recover their mental context. When tracing a bug requires jumping between ten repositories, you’re not debugging—you’re conducting archaeology.
A Realistic Example
Let’s trace an actual cross-service failure. A user tries to purchase a subscription upgrade. The request hits your API gateway, routes to the subscription service, which calls the billing service to process payment, which calls the payment provider integration, which succeeds—but then the subscription service fails to update the user record because the user service is returning stale data from a cache that was supposed to be invalidated but wasn’t because the event bus message got dropped.
Finding this bug with traditional search tools:
- Search payment service for the error. Find the log line. Twenty seconds.
- Realize the error is upstream. Search subscription service. Find the failing call. Two minutes.
- Trace the user service call. Search for the endpoint. Find three versions. Five minutes figuring out which is active.
- Search for cache invalidation logic. Find it spread across two repositories. Ten minutes.
- Search for event bus configuration. Find it in an infrastructure repo you didn’t know existed. Fifteen minutes.
- Search for who changed the event bus config recently. Git blame tells you someone made a “minor cleanup” last week. Twenty minutes.
Total time to find root cause: over an hour. Total repositories touched: six. Total context switches: dozens.
What Cross-Repository Search Should Look Like
Now imagine asking a single question: “Why is the subscription upgrade failing for users?”
A context-aware system that understands your entire architecture would:
- Identify the request flow from API gateway through all relevant services
- Trace data dependencies, including cache relationships
- Find the event bus configuration and its recent changes
- Connect the “minor cleanup” commit to the cache invalidation breakage
- Return the answer with citations to the exact files and lines involved
Not because it searched harder. Because it already understands how your repositories connect.
This is what enterprise code search needs to evolve into. Not faster keyword matching across more files, but genuine understanding of service relationships and data flows.
The Questions That Actually Matter
When you’re debugging cross-service failures, you’re not asking “where does this function live.” You’re asking:
“What services are upstream of this endpoint?”
“When did this behavior change and who changed it?”
“What data flows through this path and where can it break?”
“What other services will be affected if I deploy a fix here?”
These aren’t search queries. They’re architectural questions that require understanding your system as a connected whole.
ByteBell maintains a version-aware graph of your entire codebase—every repository, every dependency, every documented behavior. When something breaks, you don’t search across ten repos. You ask what happened, and you get an answer with receipts: exact file paths, line numbers, commit hashes. Verifiable context, not guesswork.
The Cost of Getting This Wrong
That Tuesday afternoon bug hunt has real costs. Engineer hours spent tracing connections. Customer frustration during the outage. The VP’s time spent asking for status updates instead of working on strategy.
Stripe’s research puts this starkly: engineering teams lose 42% of their time to organizational overhead. Cross-service debugging is organizational overhead with an urgent deadline.
Multi-repo code search isn’t a developer convenience feature. For teams running microservices at scale, it’s the difference between debugging in minutes and debugging in hours. Between shipping the fix before dinner and explaining to leadership why it took all week.
Your services don’t live in one repository. Your search tool shouldn’t either.
ByteBell provides cross-repository context for enterprise engineering teams. Learn how version-aware knowledge graphs with verifiable citations can reduce coordination overhead at bytebell.com.