You join a new company and you walk into a massive office building with 500 rooms across 10 floors. Every room has files, whiteboards, sticky notes, and documents left behind by people who worked there before you. Some rooms connect to other rooms in ways that are not obvious, like changing something in room 204 on the second floor will break something in room 507 on the fifth floor but nobody told you that and there is no sign on the door.
You need to find information, understand relationships, and get work done. So naturally people have tried to build tools to help you navigate this building. Lets look at what they built and why each one falls short.
The first attempt — Vector Search
Imagine you hire a librarian and tell them to go through every room and write down a rough description of what each room “feels like.” Not what it actually does, just the vibe. Room 204 has words like “authentication, token, validate” so the librarian writes down something like “security-ish room with login stuff.” Room 507 has words like “user, profile, update” so the librarian writes “user management vibes.”
Now when you ask “which room handles JWT token refresh” the librarian looks through their vibe descriptions and says “room 204 feels closest to what you are asking.” And sometimes that works. But here is the problem. The librarian has no idea what any of this code actually does. They matched words, not meaning. If someone wrote the authentication logic using unusual variable names or if the critical connection between two rooms happens through an indirect event bus rather than a direct function call, the librarian will completely miss it. They are pattern matching on the surface of the language, and code is not english. Code is logic. Two completely different looking pieces of code can do the exact same thing, and two nearly identical looking pieces of code can do completely opposite things. The librarian cannot tell the difference.
That is what vector embeddings do. Tools like claude-context and Cody turn code into numerical representations and match by similarity. It works for simple lookups but it fundamentally treats code like prose, and code is not prose. You search for “user login flow” and it finds code with similar words, but it has no understanding of the actual authentication chain, the session management, the token lifecycle, or the fact that changing the login handler in one repository will break the SSO integration in three other repositories. Vector search gives you files that look related. It does not give you understanding.
The second attempt — AST Parsers and Static Code Graphs
So someone had a better idea. Instead of matching vibes, lets actually read the structure. Hire an architect who goes through every room and draws a precise blueprint. This function calls that function. This file imports that file. This class inherits from that class. Now you have a perfect structural map of the building.
This is what tools like GitNexus, Sourcegraph with SCIP indexing, Serena, code-graph-mcp, and CodeGraphContext do. They parse your code into abstract syntax trees using tools like tree-sitter, they map function calls, they build dependency graphs. GitNexus does this particularly well with its zero-server architecture and deep MCP integration, precomputing every call chain and functional cluster at index time. Sourcegraph takes it further with cross-repository code navigation at enterprise scale.
The problem is the architect can tell you that room 204 has a pipe that connects to room 507 but they cannot tell you what flows through that pipe or why it matters. They see the wiring but not the purpose. They know that function A calls function B but they have no idea that function A calls function B specifically because there is a regulatory compliance requirement that every user action needs to be logged before the profile update happens. The business logic, the intent, the reason behind the architecture, all of that is invisible to someone who only reads blueprints.
Graphify tries to solve part of this by combining AST parsing with multimodal analysis, reading code through multiple representations beyond just the syntax tree. Its a step in the right direction but its still fundamentally building a structural graph enriched with pattern matching rather than extracting actual semantic intent. And none of these tools, not GitNexus, not Sourcegraph, not Graphify, can build semantic connections across repositories in a way that understands the business purpose behind cross-repo dependencies. They map the pipes but not the plumbing logic.
The third attempt — Just throw it at the LLM every time
So then the AI wave hit and people said forget the librarian, forget the architect, just give the raw code to a powerful AI model and let it figure everything out. And honestly this works surprisingly well because modern LLMs are genuinely good at reading code and understanding intent. You paste a file into Claude or GPT and ask what it does and the answer is usually excellent.
But here is the catch. Every morning your AI assistant wakes up with complete amnesia. They remember nothing from yesterday. So you spend the first two hours of every day walking them through the building again, showing them the rooms again, explaining the connections again. Your colleague sitting next to you is doing the exact same thing with their own assistant. The person on the next floor is doing it too. Everyone across the entire team is paying for the same tour of the same building every single day, and each person might be using a different assistant, one uses Claude Code, another uses Cursor, another uses Windsurf, another uses OpenCodex, and none of these assistants share what they learned with each other.
This is not a hypothetical cost. One developer tracked 100 million tokens of Claude Code usage over a month and found that for every 1 token Claude wrote, it consumed 166 tokens reading files. A ratio of 165 to 1. Sixty to eighty percent of all tokens consumed by AI coding agents go to file reading and navigation, not to reasoning or code generation. You are not paying for AI intelligence. You are paying for AI reading the same files over and over again.
Tools like Augment Code try to solve this with their Context Engine that processes hundreds of thousands of files through semantic dependency analysis. But Augment is cloud SaaS, your code leaves your perimeter, and it does not share context across competing copilots because no company will build a context layer that benefits their competitors.
The insight — the LLM compiler pattern
Here is where everything comes together. LLMs are the only tools that can truly understand the semantic intent of code. Not just what it looks like (vector search) or how it is structured (AST parsers) but what it actually means, why it exists, what business purpose it serves, and how it connects to other parts of the system. No other tool can do this.
The LLM compiler pattern means you use the LLM as a compiler, not as a runtime. Instead of asking the AI to understand the codebase from scratch every single session, you run the AI once across the entire codebase and have it compile the code into semantic meaning. Every file gets annotated with its purpose, its business role, its cross-repo dependencies, what would break if you changed it. All of those semantic relationships get stored as a persistent graph where the connections are not just “file A imports file B” but “file A handles the payment webhook that triggers the user notification flow in file B in a completely different repository because of the Stripe integration requirement.”
You pay the AI cost once during indexing. The understanding persists forever. Any model, any copilot, any agent can query it.
Think of it the way Google thought about the web. Google did not re-crawl the entire internet every time someone searched. They crawled once, built an index, and queried the index forever. The LLM compiler pattern does the same thing for code, except instead of building a keyword index, you are building a semantic understanding index using the only tool that can actually understand code at a business logic level.
The cost breakthrough — open source models changed everything
Now the obvious objection is that running an LLM across your entire codebase sounds insanely expensive. And two years ago it would have been. But the open source AI landscape has changed everything.
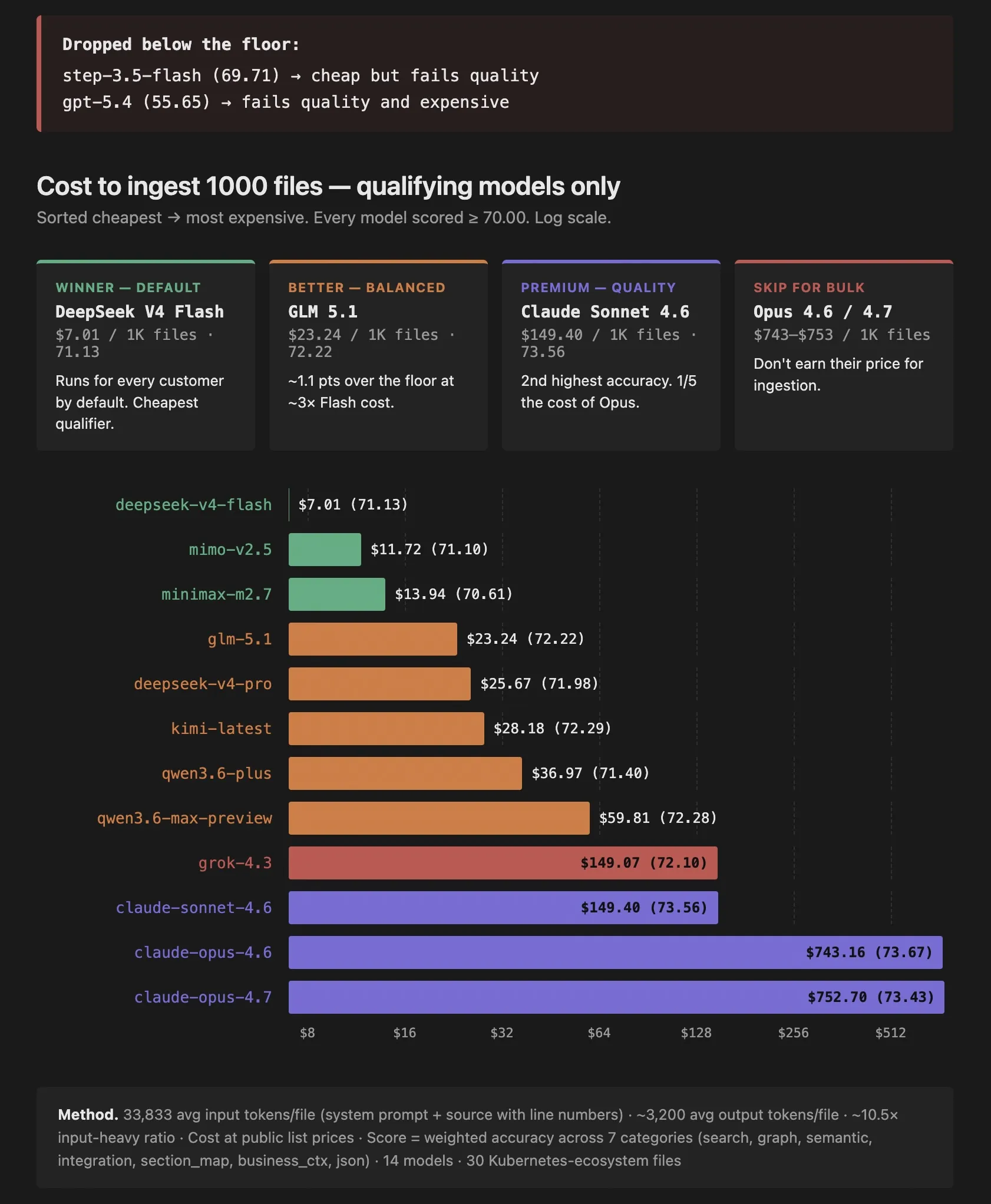
We benchmarked 14 models across 30 Kubernetes ecosystem files with roughly 33,800 average input tokens per file and scored each model across 7 categories including search accuracy, graph quality, semantic understanding, and cross-repo integration. Any model that scored below 70 points was dropped as unusable.
DeepSeek V4 Flash can semantically index 1,000 files at just 752.70 and only about 2.3 points behind in quality. GLM 5.1 sits in a balanced spot at $23.24 with 72.22 accuracy. Models like GPT 5.4 scored 55.65 which is completely unusable, and Step 3.5 Flash came in at 69.71 which looks cheap but falls below the quality floor.
What this means is that the LLM compiler pattern has gone from being a luxury that only large companies could afford to being dirt cheap enough to run on any codebase of any size. You can semantically index your entire codebase for the cost of a few coffees. The cost is no longer the bottleneck.
This is ByteBell
ByteBell is the permanent map of your building.
You point it at your repositories, all of them, monorepos, cross-repo setups, microservices architectures, the whole thing. It runs a one time semantic indexing pass using a cheap open source model like DeepSeek V4 Flash. The LLM reads every file and extracts what it does, why it exists, what business domain it belongs to, and how it connects to files in other repositories. All of that understanding gets stored in a persistent semantic graph that deploys entirely on your infrastructure via Docker, your cloud, your control, your perimeter, no code exfiltration.
From that point on, every engineer on the team, using any AI model, using any copilot, whether its Claude Code or Cursor or Windsurf or OpenCodex or Copilot or anything else, they all access the same semantic understanding through a single MCP url. Nobody rebuilds context. Nobody pays for the same tour twice. Nobody starts from zero. The semantic graph survives across sessions, across models, across agents, across the entire team.
When an engineer asks “what happens if I change the authentication flow in repo A” the model does not guess and it does not search through hundreds of files burning tokens. It looks at the semantic graph and knows exactly which files in repo B and repo C depend on that flow and why. Every answer comes back with citations to exact file paths, exact line numbers, and exact commit hashes because engineers do not trust answers without receipts.
We tested this on 150,000 files across 46 Kubernetes ecosystem repositories, roughly 8 GB of pure code. Despite feeding models 22x more context through the semantic layer, the average cost per task actually dropped from 0.22 because the model stops wasting tokens exploring dead ends. 70% less cost, 70% faster responses, about 10% more accuracy. And in cross-repository scenarios where even SOTA models with full prompt caching and claude.md completely fail to even finish the task, ByteBell is the only approach that gives the model enough understanding to actually solve the problem.
Every tool today caches files. ByteBell persists meaning. That is the difference, and that is what changes everything downstream for how engineering teams work with AI.