We Analyzed 14 LLMs on Code Understanding. Vectors Lost.
Developers kept telling us this was a stupid idea.
The idea is simple. Use an LLM to analyze every file in your codebase. For each file generate a purpose, a summary, and a business context. Store it all in a Neo4j graph with edges to every class, function, keyword, and import. Then let AI coding tools query that graph instead of re-reading raw files.
The pushback was always the same. “That’s too expensive. Just use embeddings. Just use Tree-sitter.”
So we tested it. 14 models. 30 real Kubernetes ecosystem files. 7 weighted categories. Here is what we found.
Why Vectors Don’t Work for Code
We tried embeddings first. It was our first approach a year ago. The problem is fundamental.
A function called validate() in your auth service and validate() in your form library embed to nearly identical vectors. They share zero context. A utility file and the service that imports it can embed far apart even though they are tightly coupled. Cosine similarity measures token overlap not structural relationships. Call graphs, inheritance chains, import trees — vectors flatten all of it into a single point.
Retrieval precision on real codebases was bad enough that we dropped it entirely.
Why AST Parsers Fall Short
Tree-sitter gives you exact structure. Precise, fast, language-specific. But it only tells you what the code looks like, not what it does.
When a developer asks “how do we handle failed payments” the AST cannot tell you that retryCharge() in billing/processor.ts is the answer. It has no semantic understanding. It knows the function exists and what it calls. It does not know why it exists or what business problem it solves.
What Actually Works: LLM Analysis Per File
We run an LLM over every file. The prompt asks for three things.
Purpose. One sentence on what this file does. “Handles webhook retry logic for failed Stripe payment events.”
Summary. How it does it. Key classes, functions, patterns used.
Business context. Why this file exists in business terms. “This file exists because payment failures during peak checkout caused $40K in lost revenue in Q3. The retry mechanism was added to handle transient Stripe errors.”
All three fields get stored as properties on a FileNode in Neo4j. Edges connect each file to its classes, functions, keywords, and imports. Then we run fulltext search across those semantic fields instead of vector similarity.
The result is retrieval that matches what a developer means, not what the code spells.
The Cost Objection
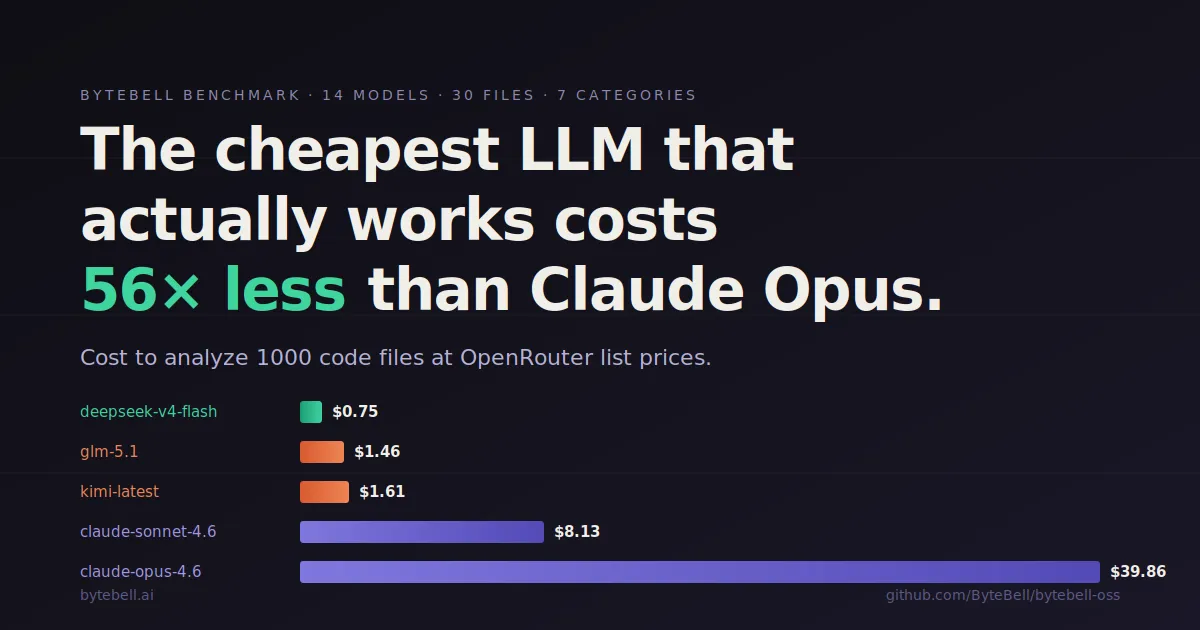
Everyone assumed this meant Opus pricing. $40 per 1000 files. Insane for a 200K file monorepo.
It doesn’t. We benchmarked 14 models and found that open source models clear the quality bar at a fraction of the cost. The right way to pick a model for bulk ingestion is not points per dollar. That rewards cheap models even when they fail. The right way is to set a quality floor and pick the cheapest model that clears it.
Floor: 70 weighted accuracy. Two models dropped out.
step-3.5-flash scored 69.71. Cheap but misses the bar by 0.29 points.
GPT 5.4 scored 55.65 at $68.91 per 1000 files. Both expensive and significantly less accurate than every alternative.
The 12 Models That Survived
| Model | Cost / 1K files | Accuracy |
|---|---|---|
| DeepSeek V4 Flash | $7.01 | 71.13 |
| MiMo V2.5 | $11.72 | 71.10 |
| MiniMax M2.7 | $13.94 | 70.61 |
| GLM 5.1 | $23.24 | 72.22 |
| DeepSeek V4 Pro | $25.67 | 71.98 |
| Kimi Latest | $28.18 | 72.29 |
| Qwen 3.6 Plus | $36.97 | 71.40 |
| Qwen 3.6 Max Preview | $59.81 | 72.28 |
| Grok 4.3 | $149.07 | 72.10 |
| Claude Sonnet 4.6 | $149.40 | 73.56 |
| Claude Opus 4.6 | $743.16 | 73.67 |
| Claude Opus 4.7 | $752.70 | 73.43 |
The spread tells the story. 107x cost difference between the cheapest and most expensive. 2.54 points of accuracy difference. That is it.
DeepSeek V4 Flash at $7.01 per 1000 files is our default for every customer. It clears the floor at the lowest cost. The 2.54 point gap to Opus costs 107x more. Not a defensible trade for bulk work.
The Real Math on a Large Codebase
A 200,000 file monorepo at DeepSeek V4 Flash pricing costs about $1,400 to index the first time. Sounds like a lot until you realize three things.
First, it is a one-time cost. ByteBell uses SHA-256 per-file diffing. When a developer pushes a commit that changes 12 files, we re-analyze 12 files, not 200,000. Ongoing cost is proportional to churn not repo size.
Second, without this index your AI coding tools re-read those files every session. A developer spending 10 per Claude Code session on a large codebase is spending $1,200 a month just on context loading. The index pays for itself in the first month.
Third, the downstream accuracy improvement is 10% to 40%. When your AI queries structured metadata with purpose, summary, and business context instead of reading raw files, it actually understands what the code does. Hallucination drops from 15-30% to under 4%.
The Research Backs This Up
We did not invent this idea in isolation.
RepoGraph (ICLR 2025) showed a 32.8% improvement on SWE-bench with graph based approaches. CodexGraph (NAACL 2025) demonstrated that graph database queries beat similarity-only retrieval. Code-Craft showed 82% better top-1 retrieval precision using LLM summaries over code graphs versus embedding based retrieval.
What we built is a production implementation of these findings. Per-file LLM analysis generating purpose, summary, and business context, stored in Neo4j, served over MCP to any AI coding tool.
The Three Tiers
Based on the benchmark we recommend three tiers for ingestion.
Default: DeepSeek V4 Flash at 7 to $28 range are equally viable.
Balanced: GLM 5.1 at $23.24 per 1000 files. Score 72.22. About 1.1 points over the floor at roughly 3x the cost of Flash. The option when a customer wants more headroom.
Premium: Claude Sonnet 4.6 at $149.40 per 1000 files. Score 73.56. Second highest accuracy on the entire benchmark. 0.11 points behind Opus at 1/5 the cost.
Opus is not on this list. Nothing about its accuracy profile justifies a 5x premium over Sonnet or a 107x premium over Flash for indexing work.
The Bottom Line
The cost gap that everyone was worried about turned out to be a model selection problem, not an architecture problem. LLM based code analysis is not expensive. Using the wrong model for LLM based code analysis is expensive.
We open sourced the full engine. The benchmark, the ingestion pipeline, the MCP server, the Neo4j schema. All of it.
github.com/ByteBell/bytebell-oss
The benchmark is fully reproducible. Clone the repo, bring your own API keys, run it on your codebase, see the numbers yourself.
If your AI coding tools keep hallucinating functions that do not exist, suggesting imports from packages you do not use, and forgetting your codebase between sessions — the retrieval layer is the problem, not the model.